

Introduction
Hello there! Today I would like to tell you about the history of machine learning.
Why the history? I think it is good to know how exactly machine learning was growing. Especially these days when it’s being developed, i.a., as a recruiting tool.
Many of us must already have dealt with such an AI software without even knowing it!
Let’s start with what actually we are going to talk about.
What is deep learning?
First we need to define what is hidden behind word AI—that is what do Artificial Intelligence, machine learning, and deep learning mean and how are they interrelated?

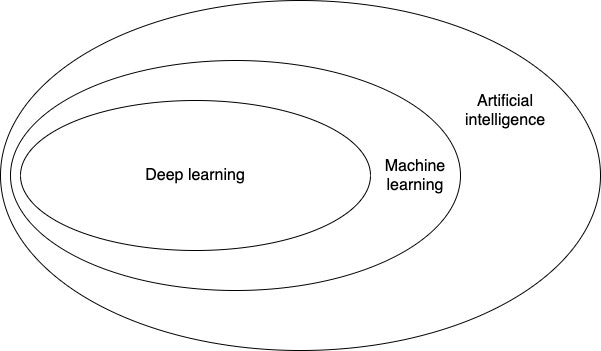
- Artificial intelligence: the effort to automate intellectual tasks normally performed by humans,
- Machine learning: the study of computer algorithms that improve automatically through experience,
- Deep learning: subcategory of ML, the goal is to create a neural network of any kind (e.g. speech recognition, face recognition)
A brief history of machine learning
Nowadays deep learning has reached a level of public attention and industry investment never seen before in the history of AI. Actually, it isn’t the first success of this domain. Today’s machine learning algorithms used in the industry aren’t deep learning algorithms.
Why is that? The answer is simple—deep learning isn’t always the right tool for problem solving. Sometimes there isn’t enough data or a given problem can be solved just by using a different algorithm. Often, under the hype, many people would like to use deep learning for solving problems of all kinds.
To avoid such situation it’s necessary to be familiar with other approaches and practice them when appropriate. But first, I would like to shortly describe the history of machine learning—its development.
1. Probabilistic modelling
It was one of the earliest forms of machine learning and it’s still widely used to this day. The most known algorithm in this category is the Naive Bayes algorithm. It is the type of machine learning classifier based on Bayes’ theorem. To start using Naive Bayes classifier you only need to know Bayes’ theorem and the foundations of statistics.
Another popular algorithm, which is also considered to be the “hello world” of modern machine learning is the logistic regression—logreg. Logreg is also useful to these days thanks to its simple nature.
2. Early neural networks
First iterations of neural network have been completely supplanted by modern approaches to neural networks. In the mid-1980s, when many people rediscovered the backpropagation algorithm—a way to train chains of parametric operations using gradient-descent optimization neural networks.
The first practical application of neural nets came in 1989. Yann LeCun combined the earlier ideas of convolutional neural networks and backpropagation. His neural network was able to solve the problem of classifying handwritten digits. This resulting network was used by the United States Postal Service in the 1990s to automate reading of ZIP codes on mail envelopes.
3. Kernel methods
After the success of neural network, new trend raised after 1990—kernel methods. Kernel methods sent the neural network into the darkness for a couple of years. Kernel methods are group of classification algorithms.
The most known algorithm from kernel methods is SVM—Support Vector Machine. SVM aims at solving classification problems by finding good decision boundaries between two sets of points belonging to two different categories.
You can think about boundary as a line which splits your two sets of training data into two categories (I skip explanation what is the SVM, because this article might be too big). At the time they were developed, SVMs were very efficient in simple classification problems and were one of the few machine-learning methods backed by extensive theory and amenable to serious mathematical analysis, making them well understood and easily interpretable.
The downside of SVMs was scaling to large datasets and didn’t provide good results. SVMs required first extracting useful representations manually (feature engineering) which is difficult.
4. Decision trees, random forests and gradient boosting machines
Decision trees are flow chart like structures that let you classify input data points or predict output values given inputs. They are easy to present and interpret. The interest starts in 2000s and by 2010 they were ofter preferred to kernel methods.
Random forest takes decision tree learning and builds a large number of specialised decision trees and then combine their outputs. Random forests are applicable to a wide range of problems. When the Kaggle (machine learning site http://kaggle.com) got started the random forests were the most popular algorithm.
In the 2014 the gradient boosting machines take down the random forests from the throne. Gradient boosting machines, like a random forest, based on combine weak prediction models, generally decision trees. It uses gradient boosting to improve any ML model by iteratively training new models that specialise in addressing the weak points of the previous models. Gradient boosting technique outperforms the random forests most of time while having similar parameters.
5. Neural networks—return
Neural networks were almost completely shunned by scientific community. A number of people still working on neural networks started to make important breakthroughs.
In 2011, Dan Ciresan from IDSIA (Dalle Molle Institute for Artificial Intelligence Research) win image classification competitions with GPU (Graphic Processing Unit) trained deep neural networks—it was the first practical success of modern deep learning.
But the big moment came in 2012 with the entry of Hinon’s group in the yearly large scale image classification challenge ImageNet. The ImageNet challenge was very difficult—it was about classifying high resolution color images into 1,000 different categories after training on 1.4 million images.
In 2011, the top five accuracy of the winning model was only 74.3% and in 2012, the top five accuracy of 83.6% —a significant breakthrough. In 2015, the winner reached the accuracy of 96.4% and the classification task of ImageNet was considered as a completely solved problem. Since 2012 deep convolutional neural networks have become the go to algorithm for all computer vision tasks, they work on all perceptual tasks.
6. What makes deep learning different
The main reason deep learning took off so quickly is that it offered a better performance on many problems. Deep learning also makes problem solving much easier, because it completely automates feature engineering.
With deep learning, you learn all features in one pass rather than having to engineer them yourself. This simplifies ML workflows, often replacing multistage pipelines with a single, end-to-end deep learning model.
Summary
As you can see, the history of machine learning is quite interesting! You can learn more if you dig deep into the above queries by yourself—I wanted to present the history in a nutshell only.
With this post, I’m planning to start a series of the machine learning-related articles which I’m super excited about.
I hope you will enjoy getting to know more about the AI in general as much as I do. :D
Thank you for your attention and see you soon! :)