Introduction
With the release of Amazon MQ service by AWS, using and managing RabbitMQ cluster in the cloud became easier. However, it comes with some pitfalls:
- there is no direct access to configuration files
- managing plugins is not possible
- cost is quite high
As in our infrastructure we use a central identity provider server and Rabbit's rabbitmq_auth_backend_http plugin, we had to develop a custom solution.
We had one single instance of RabbitMQ running on Fargate. It was receiving messages from multiple sources, as well as multiple Logstash instances were consuming data. It means that it was our single point of failure and this solution cannot be accepted while the number of clients is growing very fast. When we had to restart service, all clients were affected by downtime, even if the deployed change corresponds only to part of them. Moreover, the Fargate task didn't have a persistence layer under it, so in case of crash / restart we could lose messages currently stored in the broker. Considering these facts, we set basic requirements for new solution:
- multiple nodes clustered together to improve data safety and fault tolerance
- separate cluster of RabbitMQ for each part of the system - split of existing functions
- persistence of messages stored in broker on service restart / crash
Possible solutions
Amazon MQ
- clustering - out of the box
- plugins - doesn’t support manual plug-ins management
- persistence layer - out of the box
- management - we don’t have direct access to machine running nodes, we manage a cluster by AWS console and management plug-in
- deployment - we can make initial setup by Cloudformation, seeding has to be done manually
- price - most expensive solution
EC2
- clustering - easy to set up
- plugins - full plug-ins capability
- persistence layer - volumes attached to EC2 instance
- management - we have full access to node with SSH, aside from possibility to use management plug-in
- deployment - we can make it by e.g. Saltmaster or try to make ECS-EC2 Cloudformation template
- price - medium cost (EC2 instance for each node)
Fargate
- clustering - quite complicated to set due to dynamic nature of Fargate networking
- plugins - full plug-ins capability
- persistence layer - EFS volumes
- management - we have full access to node with AWS CLI through SSM, aside from possibility to use management plug-in
- deployment - we build Docker image containing initial seeds and with Cloudformation we set it to be run by Fargate
- price - the cheapest solution (number of Fargate tasks depends on final structure)
As it was mentioned before, due to plugin usage, we cannot use Amazon MQ. However, if your case doesn't need this feature, I would highly recommend this option. The Fargate solution looks easier to manage and deploy. All we need to build a proper Docker image is a Cloudformation template and configuration. Things like monitoring tasks status, restarting when crash etc. will be automatically managed by ECS.
Fargate deployment
Now, when we decided on Fargate, we should take a look at possible layouts of our infrastructure - how we will place our brokers in ECS services and tasks.
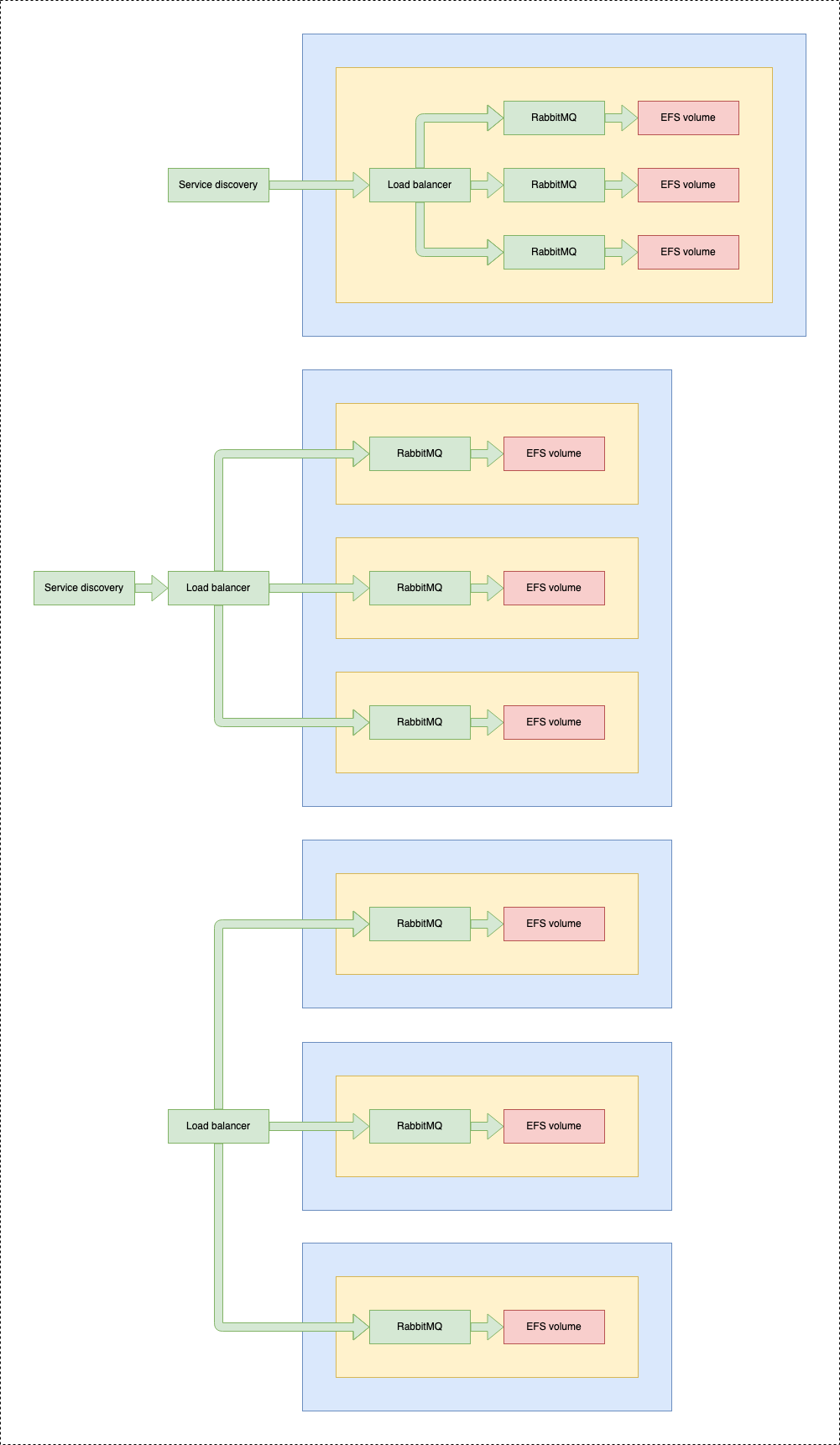
1 service - 1 task - multiple containers
This solution would consist of one service running a single task with multiple containers running RabbitMQ node each.
Pros:
- good inter-node communication performance - networking between containers placed in the same task is very fast
- easy to implement in CloudFormation
- simple nodes naming - we can set a static hostname for each container inside the task. It's important for clustering, as by default each node gets the name rabbit@<hostname>, and they must be reachable between each other in the network.
Cons:
- complicated restarting of cluster - all nodes are tightly connected together in one task. From AWS console, we cannot restart a specific container - we would have to use SSM connection to do it manually
- we must be sure to not kill the whole task - killing task means killing all containers inside it, so all cluster nodes would be unavailable at the same time
- How will we set up the cluster? - Separate service running etcd server. We made some tests before, and using etcd to manage cluster formation turned out to be a reliable solution.
- How will we handle inter-node communication? - Containers inside a task have static names, so we will use it as node names, no need to handle anything dynamic here.
- How will we restart the cluster? - Service will have SSH connection enabled in Fargate configuration (SSM). We can connect with AWS CLI to a specific container and restart it. It means that containers must be set as non-essentials to not cause restarting of the whole task.
- Where will we persist data? - EFS volumes - 1 per broker
- How will we reconnect persisted data to node after restart? - Volumes will be strictly attached to specified container in CloudFormation template, so there is no problem to define which node should use which volume after restart
1 service - multiple tasks - 1 container
Main idea is to run a single service with multiple tasks, each containing RabbitMQ broker.
Pros:
- healthcheck and restarting of tasks managed by ECS mechanisms
- we can use autoscaling to some point - adding a new node to the cluster in this case equals spawning a new task by ECS. However, me must be aware of performance hit
Cons:
- complicated way of naming nodes and reconnecting to persisted data (additional scripts needed)
- How will we set up the cluster? - Separate service running etcd server
- How will we handle inter-node communication? - Each task gets a dynamic name when spawned. That's why we will need script to assign names from known pool each time node starts
- How will we restart the cluster? - Service will have SSH connection enabled in Fargate configuration. We can connect with AWS CLI to a specific container and restart it. Containers should be set as essential, so restarting it will automatically restart the task.
- Where will we persist data? - EFS volumes - 1 per cluster
- How will we reconnect persisted data to node after restart? - As by design Fargate tasks of service are the same, we will have to assign a kind of node name for each task when it starts. This value will define at which path in the connected volume data of this node is stored.
Problem with dynamic hostnames - RabbitMQ node by default stores data in Mnesia database. It’s located in a directory named after the node name. Node name is based on the hostname of a machine running broker. In case of Fargate hostname is assigned dynamic for each task, based on ip address, so it’s not possible to reconnect to previous data without assigning some arbitrary name. Let's assume that broker starts and it gets hostname "abc" from Fargate - it will then store all data in directory "abc" on EFS volume. When the task restarts, it gets hostname "def" and will not recover data from "abc" directory. Instead, it will create new Mnesia in "def" directory and start without recovering data. In that case, we need a script which would manage custom names for nodes and assigning proper directories with data on start.
Multiple services - 1 task - 1 container
Solution assumes having multiple services running, each with one task only, which corresponds to a single node
Pros:
- healthcheck and restarting of tasks managed by ECS
- static nodes naming using service discovery mechanism
Cons:
- mode complex CloudFormation templates than in other cases (can be simplified by using AWS CDK)
- no auto-scaling - we can run only one task per service, therefore autoscaling has to be disabled
- How will we set up the cluster? - Separate service running etcd server
- How will we handle inter-node communication? - Each service would have its service discovery running. All services will belong to the same namespace. We would use these names to specify node name
- How will we restart the cluster? - As each node is a separate service, restarting it will be the same as in case of restarting other services we manage.
- Where will we persist data? - EFS volumes - 1 per broker
- How will we reconnect persisted data to node after restart? - Volumes will be strictly attached to specified service in CloudFormation template, so there is no problem to tell which node should use which volume after restart
How do we scale? We can use autoscaling only in the second layout proposition. In other cases, if we want to scale clusters up, we should rely on updating CloudFormation templates. As RabbitMQ clustering has performance limitations, when we will hit the limit we should split the responsibilities (per-feature-rabbit) or client pools (group of clients use separate URL to connect to Rabbit).
In the next part, we will discuss the CloudFormation template, which will implement the last structure - each node will correspond to a separate service with a single container.