
Sooner or later, every programmer is forced to deploy his code into a production environment. How to do it so that you can easily manage it and not hurt yourself? Does every deployment have to be a nightmare? Let’s try to answer these questions.
Deployments nightmare
Let’s start from the basics. Assume that you or your company used only one branch to deliver to customers your product(not recommended). It can look like this:

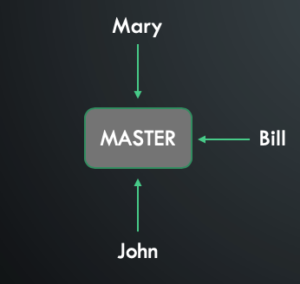
Three developers are working on features that at the end needs to be deployed to the production system. This will cause inevitable problems and I do not recommend developing straight on the branch that is used by production users:
- testing directly on the production system
- downtime
- conflicts
- and more…
Let’s try to extend this architecture by adding our feature branch. It can look like this:

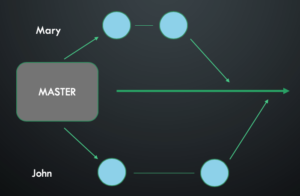
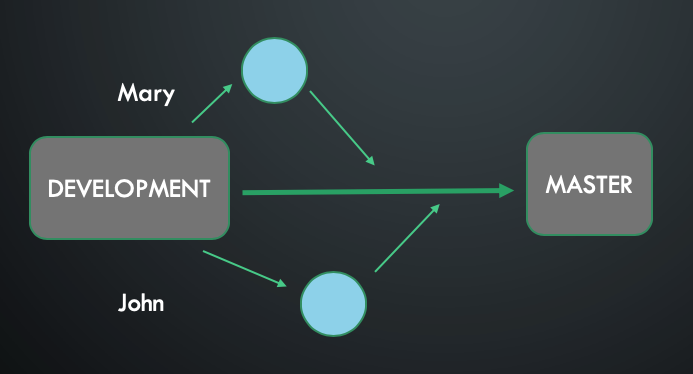
Better, but we still have one MASTER branch through which we deliver the product to customers. We will face almost the same problem as in the example before. These examples missing a basic GitHub flow and no one should use this kind of architecture in the production system.
Feature Branch – use it wisely
Now let’s try to extend deployment architecture using feature branches and testing environment. Remember that no architecture protects against committing a ‚fakap’ in the client’s system. The only thing we can do is to limit its effects as much as possible.

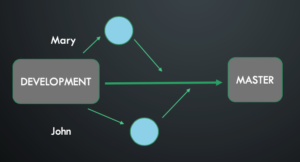
In the example above we have a testing environment from the DEVELOPMENT branch where we can push our changes to do the tests and to integrate with features that someone else develops. This gives us a comfort zone where we can play around even we can try to break the system here. Finally, when everything passes we can deploy to production system changes that were tested before.
Another advantage of using a feature branch is that you can commit your changes and gives someone to review it before pushing it. Pull Request it is the easiest way to ask someone to check your code and add a comment if it is needed.
Conclusion
Remember that no architecture protects against committing a ‚fakap’ in the client’s system. The only thing we can do is to limit its effects as much as possible. This is one way you can solve deployment issues and definitely not the only one.
Here you have some points that should help you:
- develop your features on a dedicated branch
- keep your branch up to date
- create a Pull Request before merging
- merge only whole feature not only pice of code – if feature is not ready it should stay on a feature branch